Business details
Names, addresses, phone numbers, websites, and hours.
Local directories block scrapers. Browserbase runs real browsers that extract business listings, contact info, and reviews from map and directory sites, reliably.

The Problem

The Solution
Names, addresses, phone numbers, websites, and hours.
Customer reviews, star ratings, and review counts.
Business types, services offered, and industry classifications.
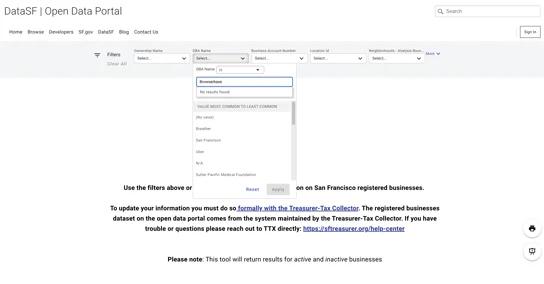
Know Your Customer
Search business registries and extract registration details, NAICS codes, and ownership data
Know Your Customer
Extract company mailing addresses from Terms of Service and Privacy Policy pages
You can extract business names, addresses, phone numbers, websites, hours, reviews, ratings, categories, photos, and geographic coordinates from local directories and map services.
Yes. Browserbase supports parallel browser sessions. You can search across hundreds of locations simultaneously, building comprehensive datasets for entire markets or countries.
Browserbase runs full browsers that handle pagination, infinite scroll, and dynamic loading. Your automation can navigate through all results just like a human user would.
Local directories block scrapers. Browserbase runs real browsers that extract business listings, contact info, and reviews from map and directory sites, reliably.
The Problem
The Solution
Names, addresses, phone numbers, websites, and hours.
Customer reviews, star ratings, and review counts.
Business types, services offered, and industry classifications.
Know Your Customer
Search business registries and extract registration details, NAICS codes, and ownership data
Know Your Customer
Extract company mailing addresses from Terms of Service and Privacy Policy pages
You can extract business names, addresses, phone numbers, websites, hours, reviews, ratings, categories, photos, and geographic coordinates from local directories and map services.
Yes. Browserbase supports parallel browser sessions. You can search across hundreds of locations simultaneously, building comprehensive datasets for entire markets or countries.
Browserbase runs full browsers that handle pagination, infinite scroll, and dynamic loading. Your automation can navigate through all results just like a human user would.
Coordinates, service areas, and geographic coverage.
Browserbase uses real browsers with built-in stealth capabilities. Features include fingerprint management, residential proxies, and human-like browsing patterns to access directories reliably.
You control how data is extracted and formatted. Most teams output JSON for database ingestion, CSV for spreadsheets, or pipe directly to CRMs and data warehouses.
Coordinates, service areas, and geographic coverage.
Browserbase uses real browsers with built-in stealth capabilities. Features include fingerprint management, residential proxies, and human-like browsing patterns to access directories reliably.
You control how data is extracted and formatted. Most teams output JSON for database ingestion, CSV for spreadsheets, or pipe directly to CRMs and data warehouses.