
SOC 2 Type II certified
Solutions
Most of the web doesn't have an API. Browserbase gives you real, headless browsers that handle dynamic content, bot detection, and auth, so your pipeline stays running instead of breaking on a Friday night.

Solutions
Most of the web doesn't have an API. Browserbase gives you real, headless browsers that handle dynamic content, bot detection, and auth, so your pipeline stays running instead of breaking on a Friday night.
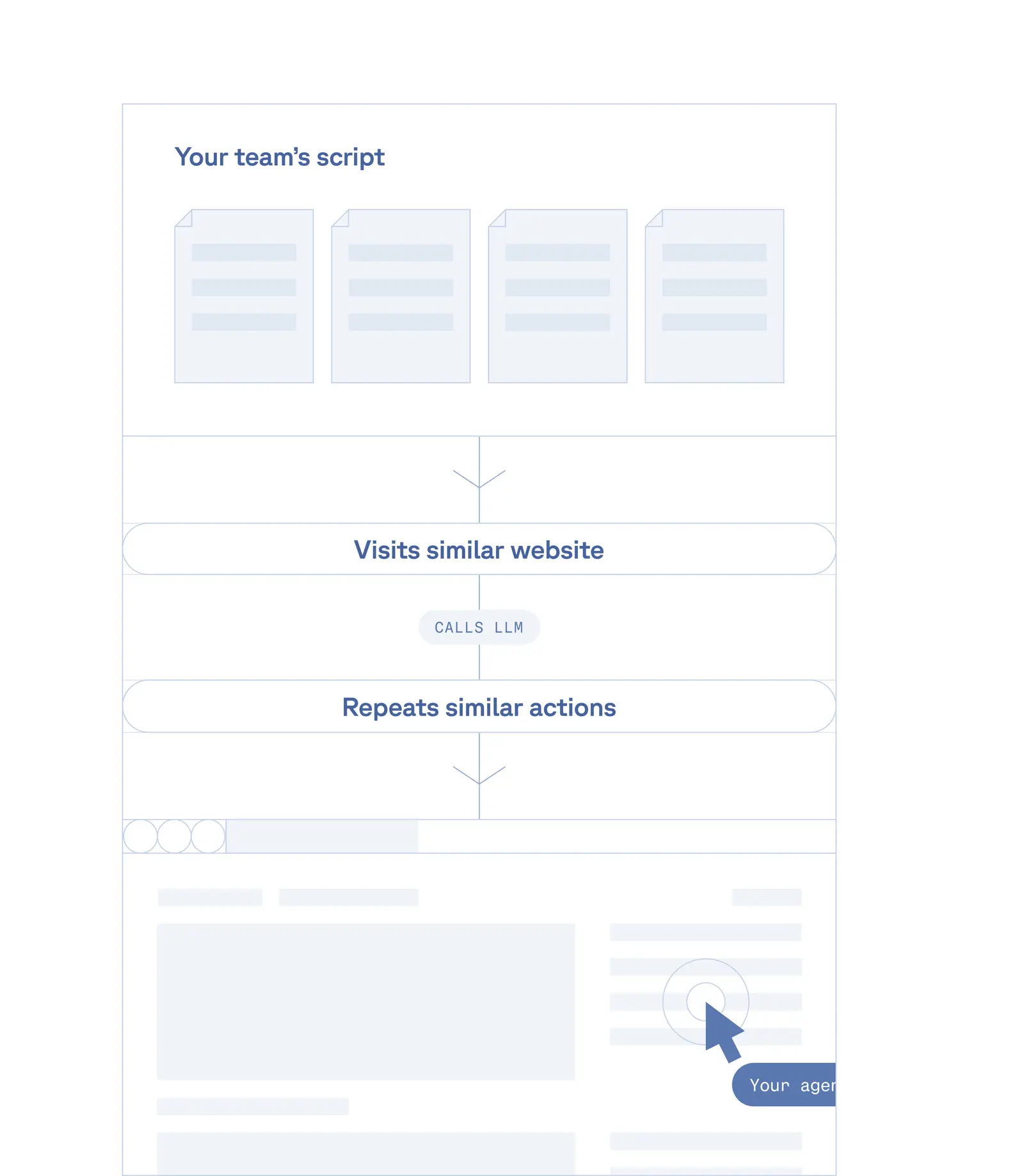
Brittle scripts, blocked requests, broken selectors, sessions timing out. Most data pipelines fail not because the logic is wrong, but because the browser layer can't keep up. Browserbase replaces the fragile parts with real headless browsers that render JavaScript, persist sessions, and bypass bot detection, out of the box. Works with Playwright, Puppeteer, Selenium, or Stagehand.
Render everything.
JS-heavy sites, SPAs, iframes, it all loads correctly.
Stay unblocked.
Built-in stealth handles bot detection and CAPTCHAs.
Stay logged in.
Sessions persist across runs without re-auth overhead.
Stop patching.
Scrapers survive UI changes without script rewrites.
Scale without ceremony.
Run thousands of parallel sessions on demand.
Built for teams that need to:
Or start with a template:
SOC 2 Type II certified

Full session isolation, no data bleed between runs

Replaces unreliable legacy tools and self-managed browser clusters
It's good to have someone reliable handling the browser management and CDN challenges so we can focus on the intelligence layer.


Brittle scripts, blocked requests, broken selectors, sessions timing out. Most data pipelines fail not because the logic is wrong, but because the browser layer can't keep up. Browserbase replaces the fragile parts with real headless browsers that render JavaScript, persist sessions, and bypass bot detection, out of the box. Works with Playwright, Puppeteer, Selenium, or Stagehand.
Render everything.
JS-heavy sites, SPAs, iframes, it all loads correctly.
Stay unblocked.
Built-in stealth handles bot detection and CAPTCHAs.
Stay logged in.
Sessions persist across runs without re-auth overhead.
Stop patching.
Scrapers survive UI changes without script rewrites.
Scale without ceremony.
Run thousands of parallel sessions on demand.
Built for teams that need to:
Or start with a template:
SOC 2 Type II certified
Full session isolation, no data bleed between runs
Replaces unreliable legacy tools and self-managed browser clusters
It's good to have someone reliable handling the browser management and CDN challenges so we can focus on the intelligence layer.