


The future of the web is agentic. Humans live in the physical world, but we increasingly find ourselves leaving our mark online (perhaps more than we’d like). We open our screens to do a little bit of everything, sometimes for fun, but often for tasks that are repetitive and boring. AI has potential to make browsing fun again, and become our trustworthy companion in navigating the web.
We’re not there yet; the web is still a wild frontier for AI. Teaching models to reason, explore, and act within it is no small feat. That’s why we partnered with Google DeepMind, leveraging the Browserbase infrastructure to help train, evaluate, and deploy the newest generation of Gemini models, reaching new state-of-the-art levels in accuracy, speed, and cost.
New Ceilings, New Opportunities
We have been working closely with Google DeepMind to help evaluate and measure the progress of their new gemini-2.5-computer-use-preview-10-2025 model. Stagehand, our fully open source framework, provides a provider-agnostic interface for computer use models, making it easy to swap and compare models against one another. To help track progress and compare different models, we added support for multiple benchmarks like OnlineMind2Web and WebVoyager, as well as our custom set of evals for both atomic actions and agents.
Over the past couple of months, we accumulated over 200 experiment runs, combining for a total of ~4,000 browser hours (almost 6 months of runtime). The results speak for themselves:
OnlineMind2Web @ 50 steps
Webvoyager @ 75 steps
The new Gemini 2.5 Computer Use models outperform every other major provider in accuracy, speed, and cost. Every model was tested through their publicly accessible API, with the same constraints on steps, timeouts, and stealth+performance environment capabilities. The new computer-use-preview model from Google presents a paradigm shift; allowing builders to create more with less, faster than ever.
Manipulating Time
By providing scalable infrastructure for running browsers in the cloud and observability to understand exactly what actions the models are taking, Browserbase helps cut the training and evaluation time from months to minutes. Instead of running the agents on a single browser and waiting for a task to complete before moving on to the next, it’s possible to branch off and train and evaluate in parallel—all at the same time.
Thanks to Browserbase’s concurrent browser infrastructure, we were able to condense ~18 browser hours into 20 minutes of total runtime.
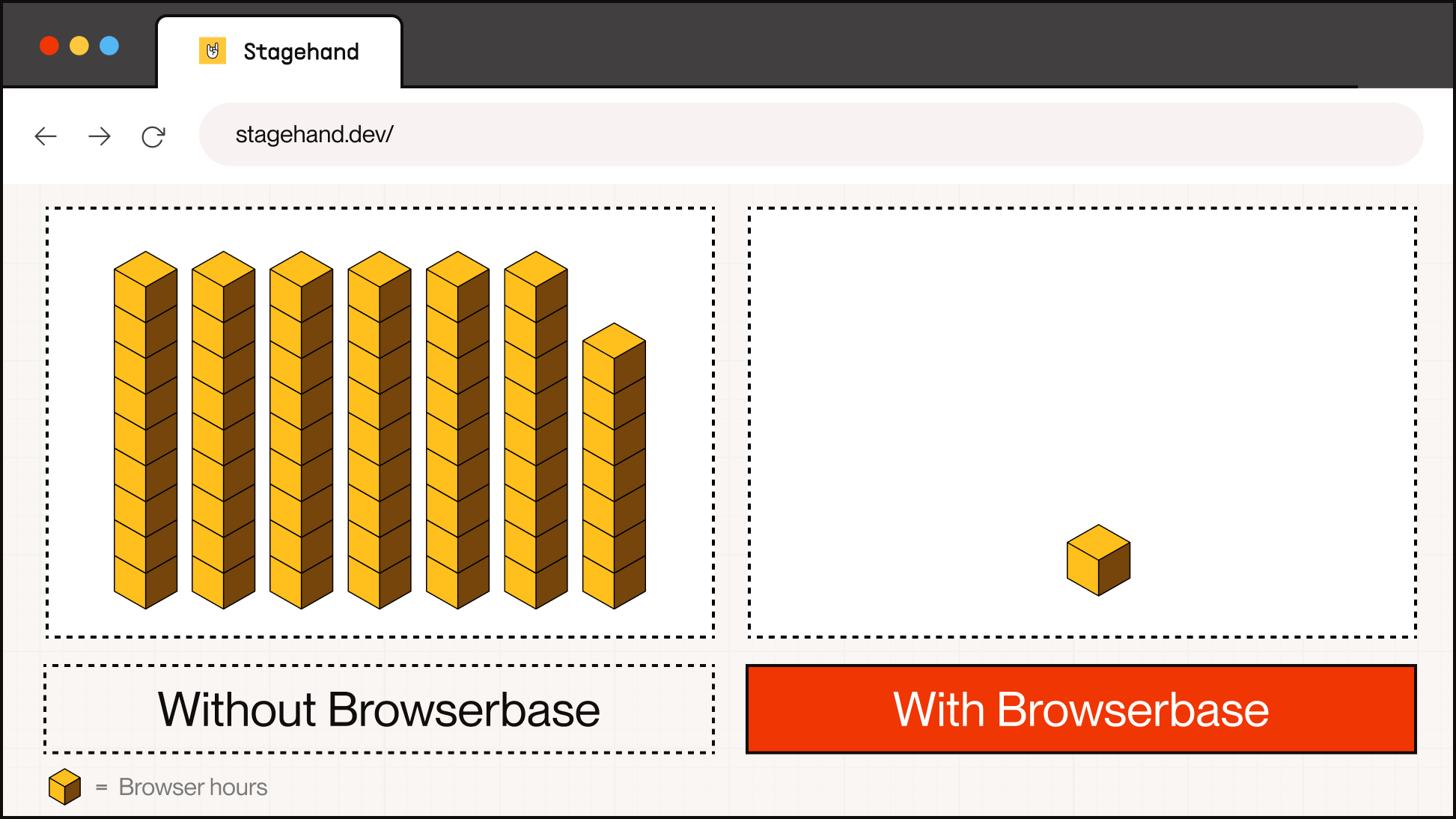
With this scale, total time for a given run is limited by an agent’s time taken to complete a single task. Faster iteration, observability into mishaps, and feedback on improvements all combine into a recipe for training capable browser agents that navigate the web better than we do (yes, many times we find ourselves trying to keep up on what the agent just did).
Challenges of Benchmarking Browser Agents
Tracking progress and testing web agents is a challenging process. Websites change, traffic gets blocked, and the goals for certain tasks become obsolete over time.
There are two main approaches to mitigating the above issues:
1. Cloning websites
This approach involves making a best-effort copy of an existing website, and having the browser agent navigate within the copied website instead of the original.
2. Using real websites
This is the approach that evaluation datasets like WebVoyager have taken. This approach involves creating a set of prompts or tasks coupled with starting URLs, and then evaluating whether the agent completed said task.
Both of these approaches are imperfect, and come with their own sets of challenges. The problem with cloned websites is that they often do not emulate the real World Wide Web, or perhaps better described as the Wild Wild Web. A static website in a controlled environment doesn’t capture the unpredictable nature of navigating a live, hosted website. There are no surprise cookie popups, captchas, iframes with ads, or slowly loading content. A lot of what makes the web challenging for agents becomes controlled.
Using real websites is also a huge challenge because of how frequently they change. A task that worked yesterday may be impossible tomorrow. For example, here is a task from the WebVoyager dataset:
Obviously, given today’s date, the above task is impossible. But what should we do with this task? Should we include it in our evaluation? It doesn’t seem like a fair evaluation, and it certainly doesn’t provide any useful data on how the agent performed. But what about other people evaluating their web agents? Did they include this task?
The easiest thing to do here is to remove or replace tasks like this, but over time, this ends up with people benchmarking against a slightly different subset of tasks. If everyone is using different tasks, then is the benchmark even a benchmark?
The Path Forward
We believe the path forward lies in transparency and collective calibration.
Instead of quietly pruning benchmarks and omitting tasks, we’re publishing the full set of 3,772 human-verified evaluations, including traces and scores for every run — successful or not. By making the raw data public, we invite others to spot ambiguous or outdated tasks, propose updates, and help shape a more stable foundation for measuring progress.
To make this process accessible, we’ve also open-sourced the Stagehand Evals CLI, enabling anyone to reproduce our experiments, inspect failures, and run their own agent comparisons locally.
We’re also providing day-1 support for the new model in Stagehand (TypeScript and Python). Getting started is as simple as:
You can also try it on Google’s official quickstart repo: https://github.com/google/computer-use-preview
If you’re not worried about benchmarks, and prefer to evaluate based on ✨ vibes ✨, we’re also launching the Browser Agent Arena. You can define a task and see which computer use model performs the best.
This partnership with Google DeepMind is just the beginning. Models are becoming more capable, soon operating a browser faster than a human can.
Instead of rebuilding the internet for AI, soon AI will be browsing alongisde us. This is an exciting future, where every interface becomes programmable and every digital task can be automated
The future is agentic, and it starts now.
We can’t wait to see what you 🅱️uild!



