One of the most painful parts of building browser infrastructure for AI is that, historically, websites would block out all web automation because of harmful activity like spam or fraud. Browsers were designed with that assumption baked in.
But the world has changed.
AI now drives real, useful automation, whether it’s agents performing research or running across hundreds of pages. These agents are legitimate users, just acting on someone’s behalf.
The problem is that browsers didn’t evolve for this. They were built to run on personal machines rather than servers. They were never meant to be programmatically controlled for long periods, and they certainly weren’t meant to act like real browsers while being automated.
At Browserbase, we’re building browser infrastructure for this new reality, where automation is a core part of how people use the web. That means our browsers must behave exactly like Chrome from the outside. The same APIs, same identity, and same long-running stability.
To do that, we had to take control of the foundation itself and crack open the black box. Just patching over Chrome at the JavaScript level didn’t give us enough control over customization.
So we forked Chromium.
Navigating the Chromium labyrinth
The sheer complexity of the Chromium source tree presents unique challenges for implementing meaningful modifications. Unlike typical software projects with clear architectural boundaries, Chromium’s functionality is distributed across multiple rendering engines, JavaScript interpreters, network stacks, and platform abstraction layers.
Identifying where to change something often means tracing a behavior through hundreds of seemingly unrelated code modules.
For example, modifying something as simple as a navigator property requires understanding how that value is generated across several subsystems. The navigator.userAgent string alone appears in platform detection modules, network headers, JavaScript bindings, and compatibility layers. A property like navigator.hardwareConcurrency touches threading libraries, worker systems, and performance monitors. All of which need to remain in sync to avoid breaking runtime expectations.
This challenge is compounded by Chromium’s rapid release cycle. New versions ship roughly every six weeks, with hundreds of commits landing daily. Each release can disrupt custom patches, forcing us to track upstream changes, validate compatibility, and rework affected code paths.
Maintaining this level of precision demands a continuous engineering investment and a deep, evolving understanding of Chromium’s internals.
Building through the chaos
When we first started building out our own custom Chromium binary, there were no reliable build guides. Most community posts are outdated or incomplete. And with a codebase that spans millions of files, every small step forward required experimentation.
So we did what any reasonable engineering team would do: we f’’ed around and found out.

The first month was pure exploration, tracing through code, guessing where to patch, and rebuilding again and again to see what broke.
Rebuilds are notoriously slow. A full Chromium build can take 3-4 days on standard development hardware like a MacBook laptop, assuming nothing fails. Every modification means another full rebuild to validate changes, and iterating on patches under those conditions quickly turns into multi-week cycles.
To stay sane, we built our own infrastructure.
Our dedicated build machine compiles Chromium in about an hour, which turns multi-day build loops into something that fits inside a productive workday. This speed has made it possible to iterate quickly and keep up with Chromium’s release cadence.
Our breakthrough was purposeful patching
When we say we “patched” Chromium, what we really mean is that we intentionally broke it.
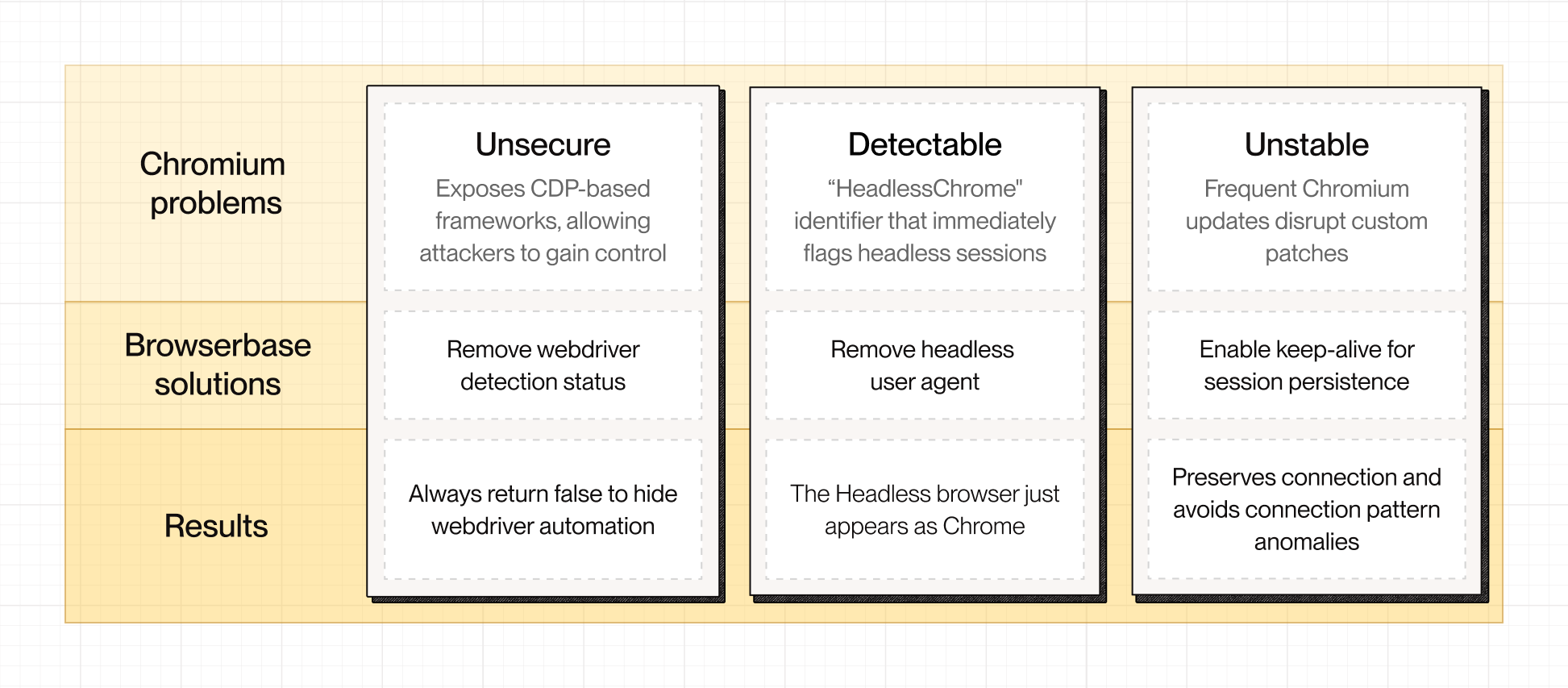
We altered behaviors that signal automation and rebuilt them to behave like normal user sessions. This looked like hundreds of patches in hundreds of different files, but we’ll examine three that our team finds particularly interesting.
We removed the navigator.webdriver flag
By default, this property exposes that automation is active. The flag is set deep inside Chromium’s rendering engine, specifically in Blink, which is the part of Chromium responsible for implementing web platform APIs like navigator.
When automation frameworks like Puppeteer or Playwright launch Chrome with the --remote-debugging-port flag, Chromium sets internal states that toggle the navigator.webdriver property to true.
We patched that behavior at the source to make navigator.webdriver always return false, no matter how the browser was launched.
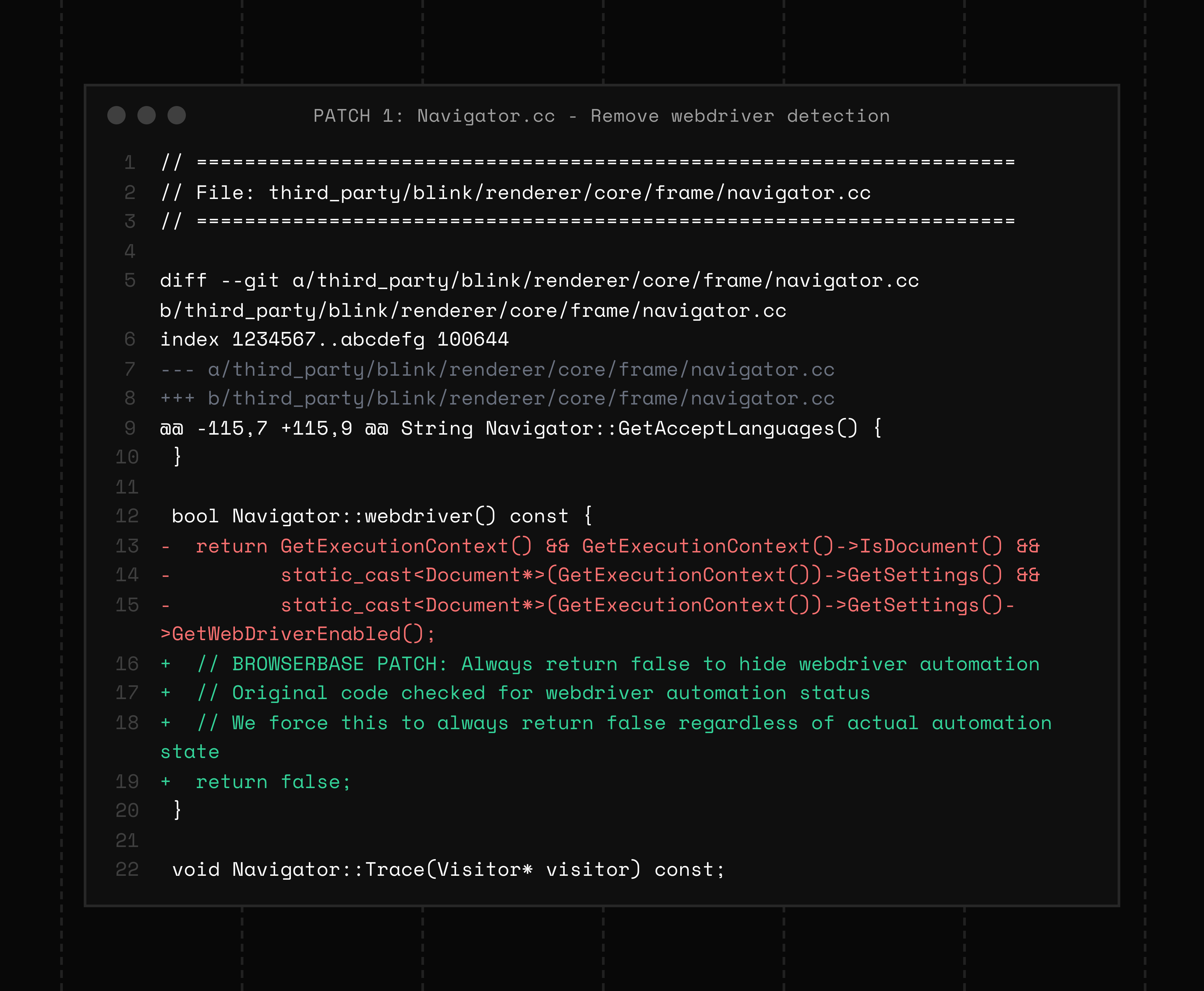
This sounds simple, but it has ripple effects. Internally, the GetWebDriver() state is propagated from Chromium’s content layer (C++) through Blink’s bindings generator into the JavaScript environment. If you patch it incorrectly, you can break feature detection logic or cause compatibility regressions in CDP.
We replaced “HeadlessChrome” with “Chrome”
But, Chrome builds the user agent from multiple sources: a product token, platform info, and metadata. If you only switch the product token, pages still see “HeadlessChrome” in other places. Our patch updates the headless product name to Chrome and keeps the metadata and CDP reporting consistent with a normal Chrome build. Requests from workers, iframes, and service workers use the same values because the Network Service pulls from the same metadata.
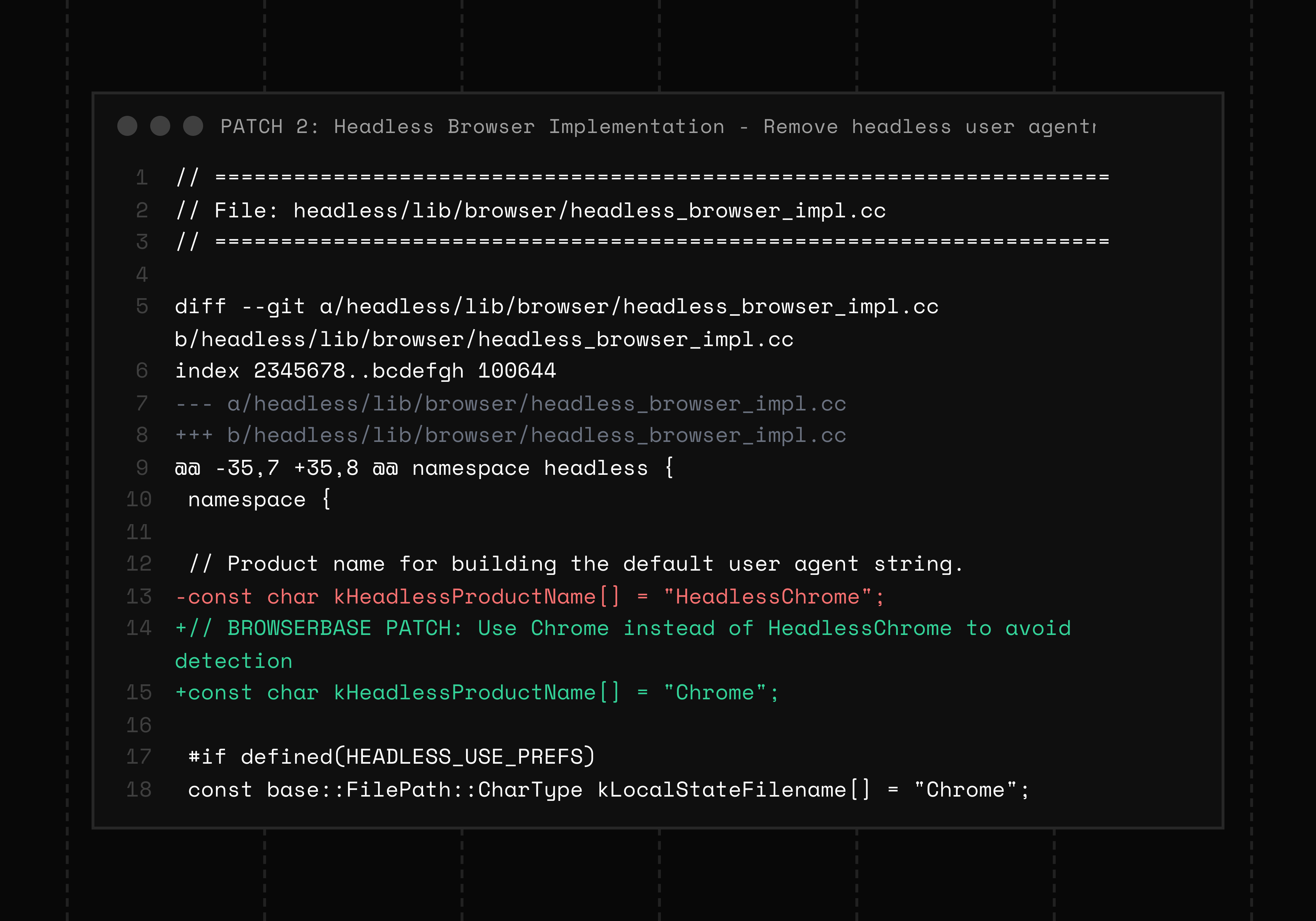
Now, the headless browser presents the same identity surfaces as Chrome beyond just the visible string.
We added persistent, long-lived session support
Normal headless browsers are short-lived. They boot, execute, and die. That behavior makes sense for testing or quick jobs, but it breaks down when we need a browser that can stay open for hours or days.
We patched this by enabling keep-alive behavior on Linux to support long-running sessions.
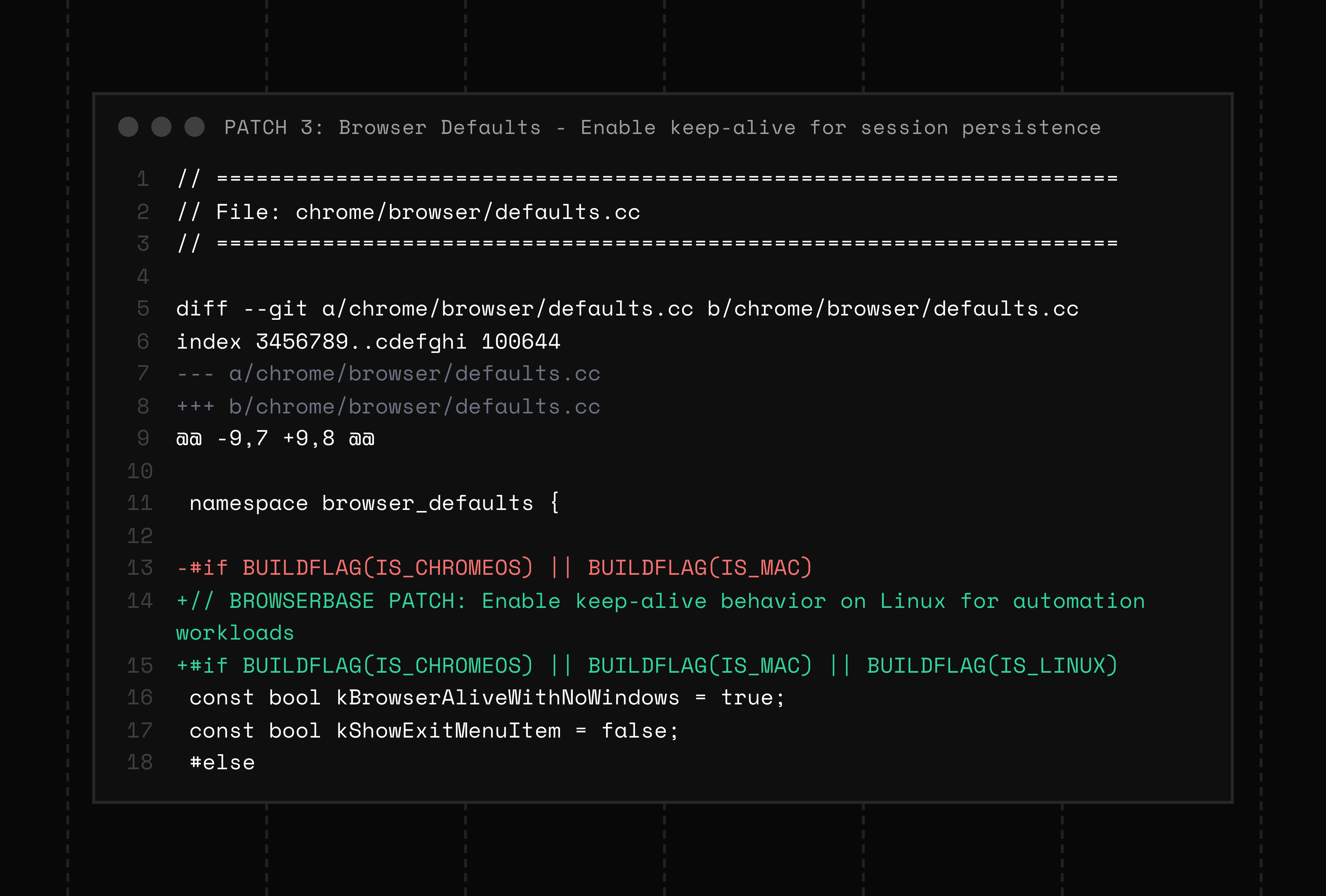
By default, Linux Chromium instances terminate when all windows close. This makes headless sessions inherently unstable when background processes are torn down, network sockets close, and session storage is lost.
Enabling kBrowserAliveWithNoWindows = true changes that behavior. The browser process remains active even when there are no visible windows, keeping its profile and CDP endpoints alive until explicitly terminated. This lets AI agents and automation systems maintain stable browser contexts with the same cookies, memory state, and connections across many requests and interactions.
Basically, this patch gives headless Chrome a heartbeat. It stays alive, keeps state, and behaves like a real browser, which is exactly what’s needed for long-running AI agents and automated workflows.
Each of these patches sounds simple, but each one required an in-depth understanding of Chromium’s internal systems, from DevTools bindings to process sandboxing to inter-thread messaging. And every one of them had to be carefully maintained across new releases.
Craft over convenience
Forking Chromium isn’t glamorous. It’s thousands of tiny experiments, failed builds, and late nights chasing invisible behavior. There was no template to build. We had to learn it, break it, and eventually make it do what we needed.
By patching Chromium itself, we’ve been able to customize the binary to meet our developers’ precise needs. We’re building for what comes next. We’re evolving the browser to fit a new era where automation is a legitimate user behavior.
This is an era where browsers are for people and systems that act on their behalf. And we’re not finished yet.